UserGuide
This document contains a detailed walk-thru of what you need to know to stage experiments on one of the PRObE clusters. If you are not familiar with the PRObE project, the PRObE home page ( http://www.nmc-probe.org/ ) has an introduction and links to the PRObE FAQ and case studies.
Contents |
Overview
There are four steps in the life cycle of running an experiment on a PRObE cluster:
| Step | Description |
|---|---|
| 1 | Join project on a PRObE cluster |
| 2 | Select and customize an operating system |
| 3 | Allocate a set of nodes, run experiments, and free the nodes |
| 4 | Conclude project |
The second and third steps can be repeated as needed. We now examine each of these steps in detail.
Joining a project on a PRObE cluster
Before applying for access to PRObE, please review the PRObE user agreement document.
All projects on PRObE clusters are created by a project head (typically a faculty member). After a project has been created, the project head will invite users to join the project by providing them with the name of the project and a link to the PRObE cluster that is hosting the project. Project heads may also provide a group name in addition to the project name, if project subgroups are being used (subgroups are an optional feature, not all projects will use them).
The current set of PRObE clusters are:
| Name | Link | Nodes | Cores | Node RAM | Node Storage | Comment |
|---|---|---|---|---|---|---|
| Marmot | https://marmot.pdl.cmu.edu/ | 128 | 256 | 16GB | 1x 2TB | General use ([hardware details]) |
| Susitna | https://susitna.pdl.cmu.edu/ | 34 | 2176 | 128GB | 1x 1TB, 2x 3TB, 1x 64GB SSD | High core count ([hardware details]) |
| Denali | https://denali.nmc-probe.org/ | 128 | 256 | 8GB | 2x 1TB | General use ([hardware details]) |
| Kodiak | https://kodiak.nmc-probe.org/ | 2020 | 2048 | 8GB | 2x 1TB | Large cluster ([hardware details]), must [reserve] to use |
| Nome | https://nome.nmc-probe.org/ | 256 | 4096 | 32GB | 1x 1TB | Large cluster ([hardware details]), must [reserve] to use |
To join a project, click the link for the appropriate PRObE cluster to get the main web page for that cluster. The next step depends on if you do or do not already have an account on that cluster from a previous project. If you do not have an account, then you must create an account while joining the project. If you already have an account, then you just need to login and request to join the project.
Creating a new account and joining a project (no previous account)
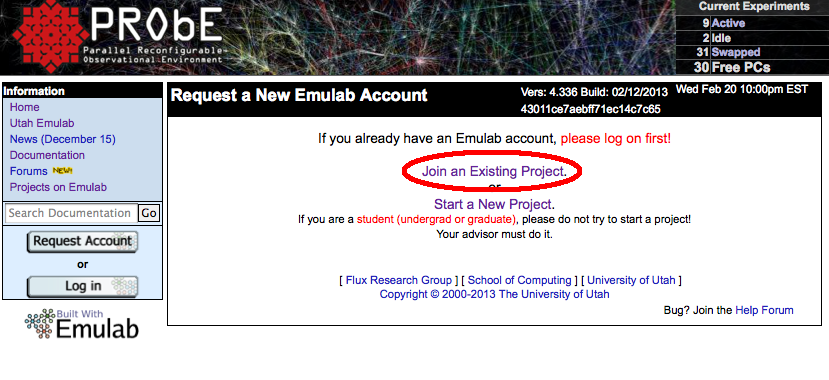
Select "Request Account" on the main page, then click on "Join an Existing Project" to access the main account creation and project joining form:

|
|
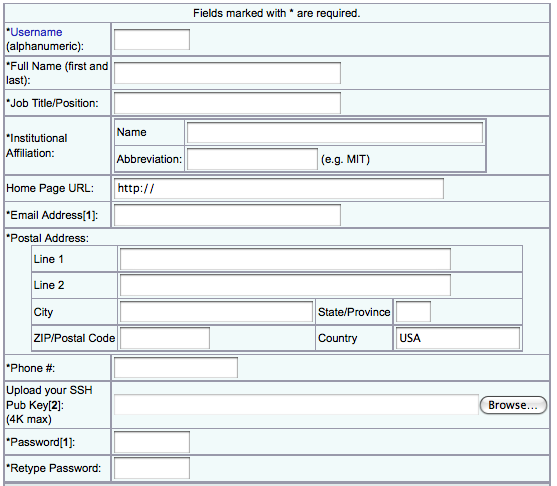
The first part of the form is used to create your new account. The most critical parts of this form are the username, full name, email address, password, and ssh keys as they are used to create your password entry.
|
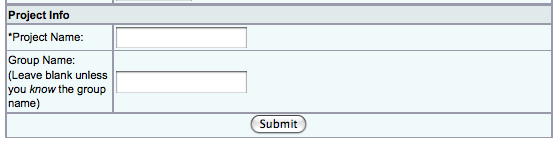
The second part of the form ("Project Info") is used to specify the project to join.
|
Once you have filled out the form, click the "Submit" button at the bottom of the page. The cluster will send you email with a link in order to verify your address. Once your address has been verified, the project head must approve your request to join the project. This is done manually, so it may take some time for the project head to complete the process. The cluster will send you email when you have been added to the project.
Joining a new project from an existing account
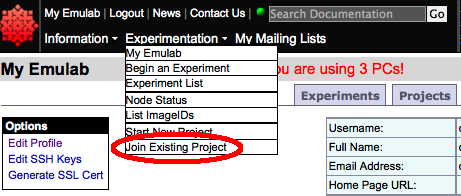
Login to your account by clicking on the "Log in" button on the main web page. Then go to the "Experimentation" pulldown and select "Join Existing Project" from the menu.
|
This will pull up the "Apply for Project Membership" form. Enter the project name (and group, if provided) and click the "Submit" button. Once your application to join the project is submitted, the project head will be notified so that the request can be approved. This is done manually, so it may take some time for the project head to complete the process. The cluster will send you email when you have been added to the project.
Accessing the cluster
After you have successfully joined a project you can use ssh to log in to the cluster's operator ("ops") node:
| Cluster | Ops node name |
|---|---|
| Marmot | marmot-ops.pdl.cmu.edu |
| Susitna | susitna-ops.pdl.cmu.edu |
| Denali | denali.nmc-probe.org |
| Kodiak | kodiak.nmc-probe.org |
| Nome | nome.nmc-probe.org |
On ops you will have access to your home directory in /usr/home and your project directory in /proj. Space in /usr/home is limited by quota, so it is a good idea to put most of your project related files in your new project's directory in /proj. The /proj directory can be read and written by all the users who are members of your project.
Ops also contains the /share directory. This directory is mounted by all the nodes and is shared across all projects. On PRObE we keep shared control scripts in /share/probe/bin.
Selecting and customizing an operating system
The next step is to select an operating system image to start with and then customize it with any additional software or configuration that you need to run your experiment. If you do not need to customize the operating system image, you can skip this step and just use one of the standard PRObE images.
Selecting an operating system image
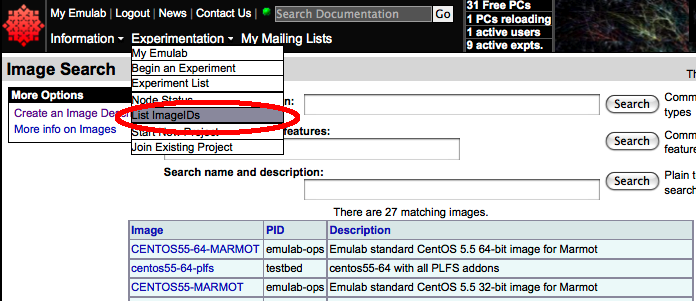
PRObE comes with a number of operating system images setup for general use. To view the list of operating systems available on the cluster, click on the "List ImageIDs" menu item from the "Experimentation" pulldown menu. The figure below shows the menu and the table it produces below. Use the table to determine the name of operating system image you want to use. For example, CENTOS55-64-MARMOT is a 64 bit version of CentOS 5.5 Linux on the Marmot cluster.
|
Customizing an operating system image
Once you have chosen an operating system image to use, you can now use it to build a customized operating system image with any additional software you need installed in it. The steps to do this are:
- create a single node experiment with the base operating system image installed
- login to the node and get a root shell
- use a package manager (apt-get, yum, etc.) to install/configure software
- manually add any local software to the image
- logout
- determine the physical name of the host your single node experiment is on
- generate a new operating system image from that host
- shutdown and delete the single node experiment
For example, here is a log of creating a new image under a project named "plfs" based on the UBUNTU12-64-PROBE Linux image. First we log into the Marmot operator node marmot-ops.pdl.cmu.edu. Next we use the "probe-makebed" script to create a single node experiment named "image" under the "plfs" project running "UBUNTU12-64-PROBE" with 1 node. Note that if you have been assigned a subgroup in your project that you want to use, you must specify the subgroup name with the "-g" flag to "probe-makebed" when creating new experiments (you only have to specify the group name when creating new experiments).
ops> /share/probe/bin/probe-makebed -e image -p plfs -i UBUNTU12-64-PROBE -n 1
probe-makebed running...
base = /usr/testbed
exp_eid = image
features =
host_base = h
image = UBUNTU12-64-PROBE
nodes = 1
proj_pid = plfs
startcmd =
making a cluster with node count = 1
generating ns file...done (/tmp/tb.pbed.59381.ns).
loading ns file as an exp... done!
swapping in the exp...
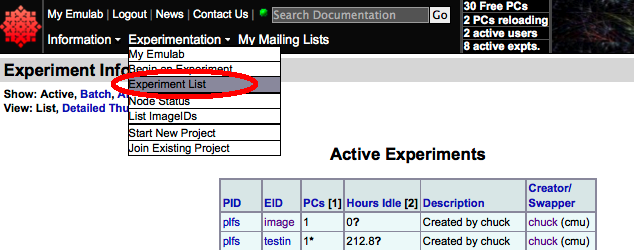
Starting a PRObE experient can take anywhere from 5 to 20 minutes depending on the number of nodes requested and the state of the hardware. To check the status of the experiment being created, click on the "Experiment List" menu item from the "Experimentation" pulldown menu. This will generate a table of "Active Experiments":
|
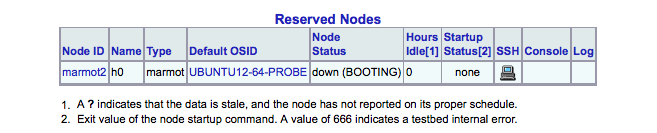
If you click on the "image" experiment (under the "EID" column) it will generate a table of all the nodes in the experiment and what their current state is (e.g. SHUTDOWN, BOOTING, up). The experiment is not considered to be fully ready until all nodes are in the "up" state.
|
Once the experiment is up, the probe-makebed script will print "all done" and you can then login to the experiment's node. The "probe-makebed" script normally names hosts as "hN.EID.PROJ" where N is the host number, EID is the name of the experiment, and PROJ is the project name. In the above example, the name of the single node in the experiment is "h0.image.plfs" and a root shell can be accessed like this from the operator node:
swapping in the exp... all done (hostnames=h0.image.plfs)! ops> ssh h0.image.plfs Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.16emulab1 x86_64) * Documentation: https://help.ubuntu.com/ h0> sudo -H /bin/tcsh h0:/users/chuck#
Now that the node is up and you have a root shell, you can use the standard package managers (apt-get, yum, etc.) to install any missing third party software that you need. While the nodes themselves do not have direct access to the Internet, the package managers in the operating system images provided by PRObE have been preconfigured to use a web proxy server on ops port 8888 to download packages.
One type of package that may be especially useful to have installed on your PRObE nodes is a parallel shell command such as mpirun or pdsh. These commands allow you to easily run a program on all the nodes in your experiment in parallel and can make the experiment easier to manage. If they are not already installed in your image, you can install them using a package manager:
apt-get -y install pdsh apt-get -y install openmpi-bin or yum install pdsh yum install openmpi etc...
In addition to installing packaged third party software, you can also manually install other third party or local software on the node. In order to do this, you must first copy the software from your home system to the ops node (either in your home directory, or in your project's /proc directory). Once the software distribution is on the ops node, you can access and install it on the local disk of the node in your experiment so that it will be part of your custom operating system image.
Generally, it makes sense to put software that does not change frequently in your custom disk image. It is not a good idea to embed experimental software that is frequently recompiled and reinstalled in your custom image as you will likely end up overwriting it with a newer version. It is best to keep software that changes often in your project's /proj directory and either run it from NFS on the nodes or use a parallel shell to install the most recent copy on the node's local disk before running it.
Once you are satisfied with the set of extra software installed on the node, then it is time to generate a customized disk image of that installation. Exit the root shell on the node and log off. Then determine the physical node name of the machine that is running your single node experiment by using either the web interface or the "host" command on ops:
ops> host h0.image.plfs h0.image.plfs.marmot.pdl.cmu.local is an alias for marmot2.marmot.pdl.cmu.local. marmot2.marmot.pdl.cmu.local has address 10.1.1.2 ops>
In this case h0.image.plfs is running on node marmot2.
Now go to the back to the cluster web pages and click on the "List ImageIDs" menu item from the "Experimentation" pulldown menu:
|
|
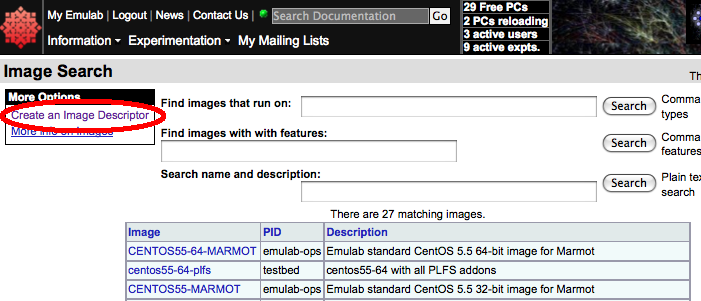
Then select "Create an Image Descriptor" from the "More Options" table:
|
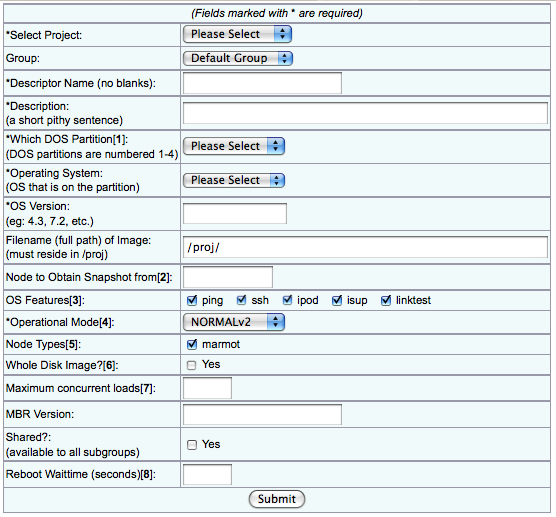
This will generate a form used to create a new disk image (shown below). For a typical Linux image do the following:
- Select the project that will own the image
- Make up a descriptor name, "ubuntu-12-64-plfs" for example
- Write a short description of the image
- Set the DOS partition to "2" (for Linux)
- Set the OS and OS versions
- Under "node to obtain snapshot from" enter the physical node name ("marmot2" in our example)
The defaults on the rest of the form should be ok. Click submit. This will cause the node to reboot, dump its disk contents to an image file, and reboot. Depending on the size of the customized operating system, it may take up to ten minutes to generate the disk image file.
|
Once the disk image has been generated, the cluster will send you an email and the new image will be added to the table on the "List ImageIDs" web page. To test the new image with a single node experiment, use probe-makebed:
ops> /share/probe/bin/probe-makebed -e test -p plfs -i ubuntu-12-64-plfs -n 1
probe-makebed running...
base = /usr/testbed
exp_eid = test
features =
host_base = h
image = ubuntu-12-64-plfs
nodes = 1
proj_pid = plfs
startcmd =
making a cluster with node count = 1
generating ns file...done (/tmp/tb.pbed.95318.ns).
loading ns file as an exp... done!
swapping in the exp...
all done (hostnames=h0.test.plfs)!
ops> ssh h0.test.plfs
Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.16emulab1 x86_64)
* Documentation: https://help.ubuntu.com/
h0> sudo -H /bin/tcsh
h0:/users/chuck#
The h0.test.plfs node should boot up with all the custom third party software you installed in the image ready to run.
Dispose of the test experiment using the "-r" flag to probe-makebed:
ops> /share/probe/bin/probe-makebed -e test -p plfs -r
probe-makebed running...
base = /usr/testbed
exp_eid = test
proj_pid = plfs
remove = TRUE!
removing experiment and purging ns file... done!
ops>
Finally, use the probe-makebed command to release the experiment used to generate the custom image:
/share/probe/bin/probe-makebed -e image -p plfs -r
Updating a customized operating system image
Sometimes you need to update a customized operating system image that you have previously created (e.g to add or upgrade software in the image). The procedure for doing this is as follows. First, create a single node experiment of the image you want to modify and log into it (don't forget to add a "-g group" arg to probe-makebed if you want to use a subgroup):
ops> /share/probe/bin/probe-makebed -e image -p plfs -i ubuntu-12-64-plfs -n 1
probe-makebed running...
base = /usr/testbed
exp_eid = image
features =
host_base = h
image = ubuntu-12-64-plfs
nodes = 1
proj_pid = plfs
startcmd =
making a cluster with node count = 1
generating ns file...done (/tmp/tb.pbed.95318.ns).
loading ns file as an exp... done!
swapping in the exp...
all done (hostnames=h0.image.plfs)!
ops> ssh h0.image.plfs
Welcome to Ubuntu 12.04.1 LTS (GNU/Linux 3.2.16emulab1 x86_64)
* Documentation: https://help.ubuntu.com/
h0> sudo -H /bin/tcsh
h0:/users/chuck#
Next, add or modify the software on the single node experiment as needed. Then log out and determine the physical name of the node the experiment is running on using the web interface or the "host" command on ops:
ops> host h0.image.plfs h0.image.plfs.marmot.pdl.cmu.local is an alias for marmot8.marmot.pdl.cmu.local. marmot8.marmot.pdl.cmu.local has address 10.1.1.8 ops>
Then go to the cluster web page and click on the "List ImageIDs" menu item from the "Experimentation" pulldown menu:
|
|
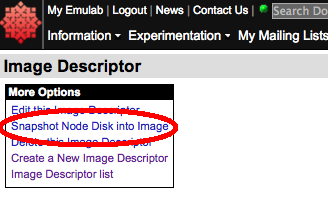
In the table of available images, click on the image name of the image you are updating ("ubuntu-12-64-plfs" in our example). Then on that image's web page, click on "Snapshot Node Disk into Image" under the "More Options" menu:
|
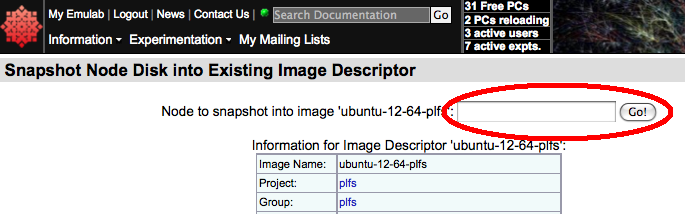
This will bring up the snapshot form. Enter the physical node name in
the box and click "Go!" to update the snapshot. Depending on the
size of the image, the snapshot update may take up to ten or so minutes to
complete.
|
Once the snapshot is complete (the system will send you email), you can dispose of the experiment using probe-makebed with "-r":
/share/probe/bin/probe-makebed -e image -p plfs -r
Allocating a set of nodes, running experiments, freeing the nodes
Once you have prepared an operating system image, you are now ready to start running multi-node experiments on the PRObE cluster using it.
Node allocation
Multi-node experiments can easily be allocated using the "-n" flag of the probe-makebed script. For example:
/share/probe/bin/probe-makebed -e exp -p plfs -i ubuntu-12-64-plfs -n 64
This command will create a 64 node experiment with hostnames h0.exp.plfs, h1.exp.plfs, etc. all the way to h63.exp.plfs running the ubunutu-12-64-plfs operating system image. (Don't forget to add a "-g group" flag to probe-makebed if you want to use a specific subgroup in a project.)
Note that each time a PRObE experiment is created, a new set of nodes is allocated from the free machine pool and initialized with the specified operating system image. Local node storage is not preserved when you delete an experiment and then recreate it later. Local storage is also not preserved if PRObE swaps your experiment out for being idle for too long. Always save critical data to a persistent storage area such as your project's /proj directory.
Boot time node configuration
It is common to want to do additional node configuration on PRObE nodes as part of the boot process. For example, you may want to:
- setup a larger local filesystem on each node
- setup passwordless ssh for the root account
- configure a high speed network (e.g. Infiniband)
- allow short hostnames to be used (e.g. "h0" vs "h0.exp.plfs")
- change kernel parameters (e.g. VM overcommit ratios)
You may also want to do other experiment-specific operations as well. One way to do this is to use the "-s" flag to "probe-makebed" to specify a startup script to run as part of the boot process.
The /share/probe/bin/generic-startup is a sample startup script that you can copy into your own directory and customize for your experiment. The generic-startup script runs a series of helper scripts like this:
#!/bin/sh -x
exec > /tmp/startup.log 2>&1
sudo /share/probe/bin/linux-fixpart all || exit 1
sudo /share/probe/bin/linux-localfs /l0 64g || exit 1
sudo /share/probe/bin/probe-localize-resolv || exit 1
/share/probe/bin/probe-sshkey || exit 1
sudo /share/probe/bin/probe-network --big --eth up --fge up \
--ib connected || exit 1
echo "startup complete."
exit 0
The "exec" command at the beginning of the script is used to redirect the script's standard output and standard error streams to the file /tmp/startup.log. This allows you to login and review the script's output for error messages if it exits with non-zero value (indicating an error). Note that the script runs under your account, so it uses the "sudo" command for operations that require root privileges.
The next two commands ("linux-fixpart" and "linux-localfs") create and mount a new local filesystem. Systems disks on PRObE nodes are configured with four partitions. The first three are normally fixed in size and used for operating system images and swapping. They typically take up the first 13GB of the system disk. The disk's fourth partition is free and can be used to create additional local storage on the remainder of the disk.
The linux-fixpart command checks to make sure the fourth partition is setup properly on the system disk, or for non-boot disks it makes one big partition. This script takes one argument than can be a disk device (e.g. /dev/sdb), the string "all," or the string "root." For the "all" setting, the script runs on all local devices matching the "/dev/sd?" wildcard expression. The "root" setting is a shorthand for the disk where "/" resides.
The linux-localfs command creates a filesystem of the given size on the fourth partition of the system disk and mounts it on the given mount point (/l0). The size can be expressed in terms of gigabytes (e.g. "64g"), megabytes (e.g. "16m"), or the default of 1K blocks. If a size is not given, then the script uses the entire partition. In addition to the system disk, some PRObE nodes have additional drives that experiments can use (see the table above for details). This script has two flags. The "-d device" flag allows you to specify a device ("root" is the default, and is an alias for the system disk). The "-t type" allows you to specify a filesystem type (the default is "ext2").
The "probe-localize-resolv" script modifies /etc/resolv.conf on a node to allow for short hostnames to be used (by updating the "search" line). This allows you to use short hostnames like "h0" instead of "h0.image.plfs" in all your scripts and configuration files.
The "probe-sshkey" command sets up passwordless ssh access for the root account on the nodes. By default it uses a built in RSA key with a null pass phrase, but you can also specify your own id_rsa key file on the command line if you don't want to use the default key.
Finally the "probe-network" script is used to configure additional network interfaces on the PRObE nodes. By default, each PRObE node only has one network interface configured and that interface is the control ethernet network. The control network is slow and should not be used for performance measurements. In addition to the control network interface, PRObE nodes have up to three additional high speed network interfaces that can be used for experiments:
| Cluster | Data Network(s) |
|---|---|
| Marmot | Gigabit Ethernet, Infiniband |
| Susitna | Gigabit Ethernet, 40GB Ethernet, Infiniband |
| Denali | Infiniband |
| Kodiak | Infiniband |
| Nome | 2x Gigabit Ethernet, 20 GB Infiniband |
The "probe-network" script takes the following flags:
- Gigabit Ethernet: "--eth MODE" where MODE is either "up" or "down"
- 40GB Ethernet: "--fge MODE" where MODE is either "up" or "down"
- Infiniband: "--ib MODE" where mode is "down," "connected," or"dgram"
- "--big" means use a larger ARP table for Linux
The "--big" flag may be useful on Kodiak when you are communicating with a large number of nodes and overflowing the kernel ARP table (the Linux kernel will complain with a "Neighbor table overflow" error).
In addition to configuring data network interfaces, the "probe-network" script also adds hostnames to /etc/hosts for these interfaces. It appends "-dib" to the hostname for Infiniband, "-deth" for Gigabit ethernet, and "-dfge" for 40GB Ethernet. So, if you are on node h1 and enable the Infiniband and Gigabit ethernet data networks, the hostname "h1-dib" will point to the IP address of the Infiniband interface and "h1-deth" will point to the IP address of the data Gigabit Ethernet interface. Plain "h1" will continue to point to the IP address of h1's control network interface. The hostname "h1-dfge" will be used for 40GB Ethernet (if available).
Example node allocation
Here is an example of allocating a three node experiment named "test" under the "plfs" project using the "ubuntu10-64-plfs-v2" image with the generic startup script shown above:
% /share/probe/bin/probe-makebed -n 3 -e test -p plfs \
-i ubuntu10-64-plfs-v2 -s /share/probe/bin/generic-startup
probe-makebed running...
base = /usr/testbed
exp_eid = test
features =
host_base = h
image = ubuntu10-64-plfs-v2
nodes = 3
proj_pid = plfs
startcmd = /share/probe/bin/generic-startup
making a cluster with node count = 3
generating ns file...done (/tmp/tb.pbed.68767.ns).
loading ns file as an exp... done!
swapping in the exp...
all done (hostnames=h[0-2].test.plfs)!
%
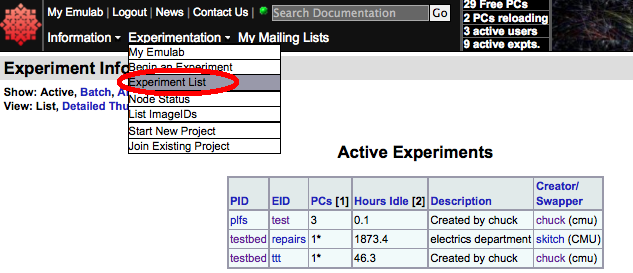
To check the status of the experiment as it comes up, click on the "Experiment List" menu item from the "Experimentation" pulldown menu. This will generate a table of "Active Experiments":
|
Then click on the "test" experiment (under EID) and it will generate a web with the following table at the bottom:
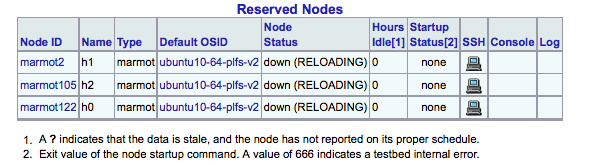
|
You can reload this web page as often as you like to check on the experiment. When the experiment is fully up, you can easily check to see if the generic startup script ran without an error on all the nodes by checking the "Startup Status" column, as shown below. A successful run of the startup script will put a zero in this column. If you are working with a very large number of nodes (e.g. on Kodiak), then you can click on the "Startup Status" header at the top of the table to sort it by startup status (e.g. so that all the failures are clustered in one place).
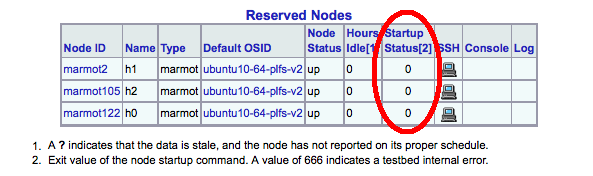
|
Once the systems are up, you can login to one of them to verify that the generic startup script ran by checking for the /l0 filesystem, testing that passwordless root ssh works, or seeing if the Infiniband network interface is up:
ops> ssh h2.test.plfs Linux h2.test.plfs.marmot.pdl.cmu.local 2.6.32-24-generic #38+emulab1 SMP Mon Aug 23 18:07:24 MDT 2020 x86_64 GNU/Linux Ubuntu 10.04.1 LTS Welcome to Ubuntu! * Documentation: https://help.ubuntu.com/ Last login: Fri Feb 22 14:29:59 2020 from ops.marmot.pdl.cmu.local h2> ls /tmp/startup.log /tmp/startup.log h2> df /l0 Filesystem 1K-blocks Used Available Use% Mounted on /dev/sda4 66055932K 53064K 62647428K 1% /l0 h2> sudo -H /bin/tcsh h2:/users/chuck# ssh h0 uptime 14:30:33 up 49 min, 0 users, load average: 0.01, 0.01, 0.00 h2:/users/chuck# ping -c 1 h0 PING marmot122.marmot.pdl.cmu.local (10.1.1.122) 56(84) bytes of data. 64 bytes from marmot122.marmot.pdl.cmu.local (10.1.1.122): icmp_seq=1 ttl=64 time=0.151 ms --- marmot122.marmot.pdl.cmu.local ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.151/0.151/0.151/0.000 ms h2:/users/chuck# ping -c 1 h0-dib PING h0-dib (10.3.0.122) 56(84) bytes of data. 64 bytes from h0-dib (10.3.0.122): icmp_seq=1 ttl=64 time=1.45 ms --- h0-dib ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 1.450/1.450/1.450/0.000 ms h2:/users/chuck#
You can access the nodes remotely via ssh proxy. Add the following to your ~/.ssh/config file:
#####PRObE
Host *.denali.nx
ProxyCommand ssh denali.nmc-probe.org -W %h:%p
Host *.kodiak.nx
ProxyCommand ssh kodiak.nmc-probe.org -W %h:%p
Host *.marmot.pdl.cmu.local
ProxyCommand ssh marmot-ops.pdl.cmu.edu -W %h:%p
Host *.susitna.pdl.cmu.local
ProxyCommand ssh susitna-ops.pdl.cmu.edu -W %h:%p
#####/PRObE
Running experiments
Once your experiment has been allocated and the boot-time initialization has successfully run on all the nodes, then you are ready to run your software on the nodes. While the details of how to do this depend on the kinds of software being used, the general pattern for running an experiment on PRObE nodes is:
- start up your application on the nodes
- benchmark, simulation, or test the application
- collect and save results
- shutdown your application on the nodes
The script /share/probe/bin/emulab-listall will print a list of all the hosts in your current experiment:
h2:/# /share/probe/bin/emulab-listall h0,h1,h2 h2:/#
The output of emulab-listall can be used to dynamically start or shutdown applications without having to hardwire the number of nodes or their hostnames. The "--separator" flag to emulab-listall can be used to change the string separator between hostnames to something other than a comma.
For small experiments, starting or shutting down your application one node at a time may be fast enough, but it may not scale well for for larger experiments (e.g. a thousand node experiment on Kodiak). In this case, it pays to use a parallel shell such as mpirun or pdsh to control your application. The script /share/probe/bin/emulab-mpirunall is a simple example frontend to the mpirun command that passes in the list of hostnames of the current experiment. Here is an example of using this script to print the hostname of each node in the experiment in parallel:
h2:/# /share/probe/bin/emulab-mpirunall hostname mpirunall n=3: hostname h2.test.plfs.marmot.pdl.cmu.local h1.test.plfs.marmot.pdl.cmu.local h0.test.plfs.marmot.pdl.cmu.local h2:/#
A more practical example is to use a script like emulab-mpirunall to run an init-style application start/stop script across all the nodes in the experiment in parallel. The exit value of mpirun can be used to determine if there were any errors.
Freeing the nodes
Before you free your nodes, make sure you have copied all important data off of the nodes' local storage into your project's /proj directory. Data stored on the nodes' local disk is not preserved and will not be available once the nodes are freed.
To free your nodes, use the "-r" flag to probe-makebed:
ops> /share/probe/bin/probe-makebed -e test -p plfs -r
probe-makebed running...
base = /usr/testbed
exp_eid = test
remove = TRUE!
removing experiment and purging ns file... done!
ops>
This operation shuts down all your nodes and puts them back in the system-wide free node pool for use by other projects.
Issues to watch for
There are a number of points to be aware of and watch for when using PRObE clusters.
Using the wrong network for experiments
Applications that require high-performance networking in order to perform well should use one of the cluster's data networks for I/O rather than the control ethernet. To check network usage under Linux, use the "/sbin/ifconfig -a" command and look at the "RX bytes" and "TX bytes" for each interface. If you think you are running your experiments over Infiniband and the counters on the "ib0" interface are not increasing, then something is not configured properly.
Not copying result data to persistent storage
Applications that collect performance measurements or test data should save their results on persistent storage (e.g. your project's /proj directory) before the nodes are released or swapped out due to being idle for too long. Data on local drives is not preserved after an experiment is shutdown.
Allowing an experiment to be shutdown for being idle or running too long
The PRObE control nodes monitor all allocated nodes to ensure that they are being used. If an experiment sits idle for too long, then it is shutdown ("swapped out") so other users can use the idle nodes. To avoid this it is best to keep track of how long your allocated nodes are idle. The system also limits the overall lifetime (duration) of an experiment.
If you need to increase the idle timeout, this can be done by changing the experiment settings. Click on the "Experiment List" menu item from the "Experimentation" pulldown menu. This will generate a table of "Active Experiments":
|
|
Click on the "EID" of the experiment to change in the "Active Experiments" table.
One the web page for the selected experiment comes up, select "Modify Settings" from the menu on the left side of the page:
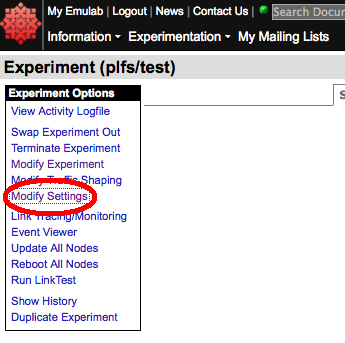
|
This will produce the "Edit Experiment Settings" table. The two key settings are:
- Idle-Swap
- Max Duration
These values can be increased (to a limit) from their defaults, if needed.
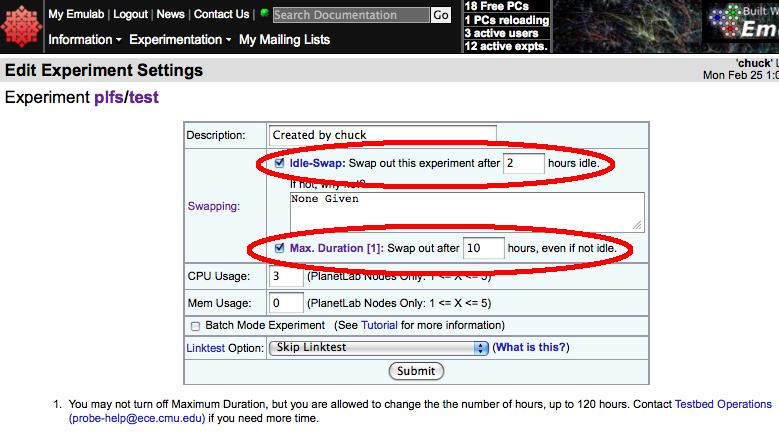
|
Hardware problems
Given the number of machines in the PRObE clusters, there is a chance that you may encounter a node with hardware problems. There are a number of ways these kinds of problems can manifest themselves. Here is a list of symptoms to be aware of:
- Hung node
- Node stops responding to network requests and shows up as "down"
- Crashed node
- Node crashes and reboots, killing anything currently running on it
- Dead data network interface
- Node boots, but is unable to communicate over a data network (e.g. Infiniband)
- Kernel errors
- The kernel runs, but logs errors to the system log/console
To check for the kernel reporting errors, use the dmesg command.
To report a possible hardware issue, use the system contact information on the cluster web page.
Concluding a project
Once you have finished using a PRObE cluster, you should:
- copy all important data from ops to your local system
- reduce your disk space using on PRObE so it is available for others to use
- let the head of your project know your work is complete and your part of the project can be deactivated
When writing up results for work generated with PRObE systems, please include an acknowledgment for PRObE in your papers, as described [[1]].
XXX: say something about migrating projects between PRObE clusters (e.g Marmot/Denali to Kodiak). The main issue will be copying filesystem images and supporting files.